
Extract, Define, Canonicalize: An LLM-based Framework for Knowledge Graph Construction
FEBRUARY 25, 2025
Ximei Xu, ximeixu79@gmail.com
In this blog, I will introduce the paper "Extract, Define, Canonicalize: An LLM-based Framework for Knowledge Graph Construction". This paper presents Extract-Define-Canonicalize (EDC), an LLM-based three-phase framework that addresses the problem of knowledge graph construction by open information extraction followed by post-hoc canonicalization.
Introduction & Background
This paper proposes an approach to constructing knowledge graphs that leverages large language models (LLMs) in a structured manner.
Knowledge Graph Construction
- Traditional methods typically addressed knowledge graph construction (KGC) using “pipelines”, comprising subtasks like entity discovery, entity typing, and relation classification.
- Thanks to advances in pre-trained generative language models (e.g., T5 and BERT), more recent works instead frame KGC as a sequence-to-sequence problem and generate relational triplets in an end-to-end manner by fine-tuning these moderately-sized language models.
- The success of large language models (LLMs) has pushed this paradigm further: current methods directly prompt the LLMs to generate triplets in a zero/few-shot manner.
- Problem: These models face difficulties scaling up to general text common in many real-world applications as the KG schema has to be included in the LLM prompt.
- The Extract-Define-Canonicalize (EDC) framework proposed in this paper circumvents this problem by using post-hoc canonicalization (and without requiring fine-tuning of the base LLMs).
Open Information Extraction and Canonicalization
Standard (closed) information extraction: It requires the output triplets to follow a pre-defined schema, e.g. a list of relation or entity types to be extracted from.
Open information extraction (OIE): It does not have such a requirement.
Recent studies have found LLMs to exhibit excellent performance on OIE tasks.
- Problem: The relational triplets extracted from OIE systems are not canonicalized, causing redundancy and ambiguity in the induced open knowledge graph.
- Current solutions: An extra canonicalization step is required to standardize the triplets.
- In case a target schema is present: “Alignment”.
- In case no target schema is available: Clustering.
- However, clustering-based methods are prone to over-generalization, e.g., it may put “is brother of”, “is son of”, “is main villain of”, and “was professor of” into the same relation cluster.
Extract-Define-Canonicalize (EDC): It is more general compared to the existing canonicalization methods.
- EDC works whether a target schema is provided or not.
- EDC alleviates the over-generalization issue, by allowing the LLMs to verify if a transformation can be performed (instead of solely relying on the embedding similarity).
Method
The proposed LLM-based three-phase framework is called Extract-Define-Canonicalize (EDC): open information extraction followed by schema definition and post-hoc canonicalization. Given input text, the goal here is to extract relational triplets in a canonical form such that the resulting KGs will have minimal ambiguity and redundancy. When there is a predefined target schema, all generated triplets should conform to it. In the scenario where there is not one, the system should dynamically create one and canonicalize the triplets with respect to it. Figure 1 shows an overview of the framework.
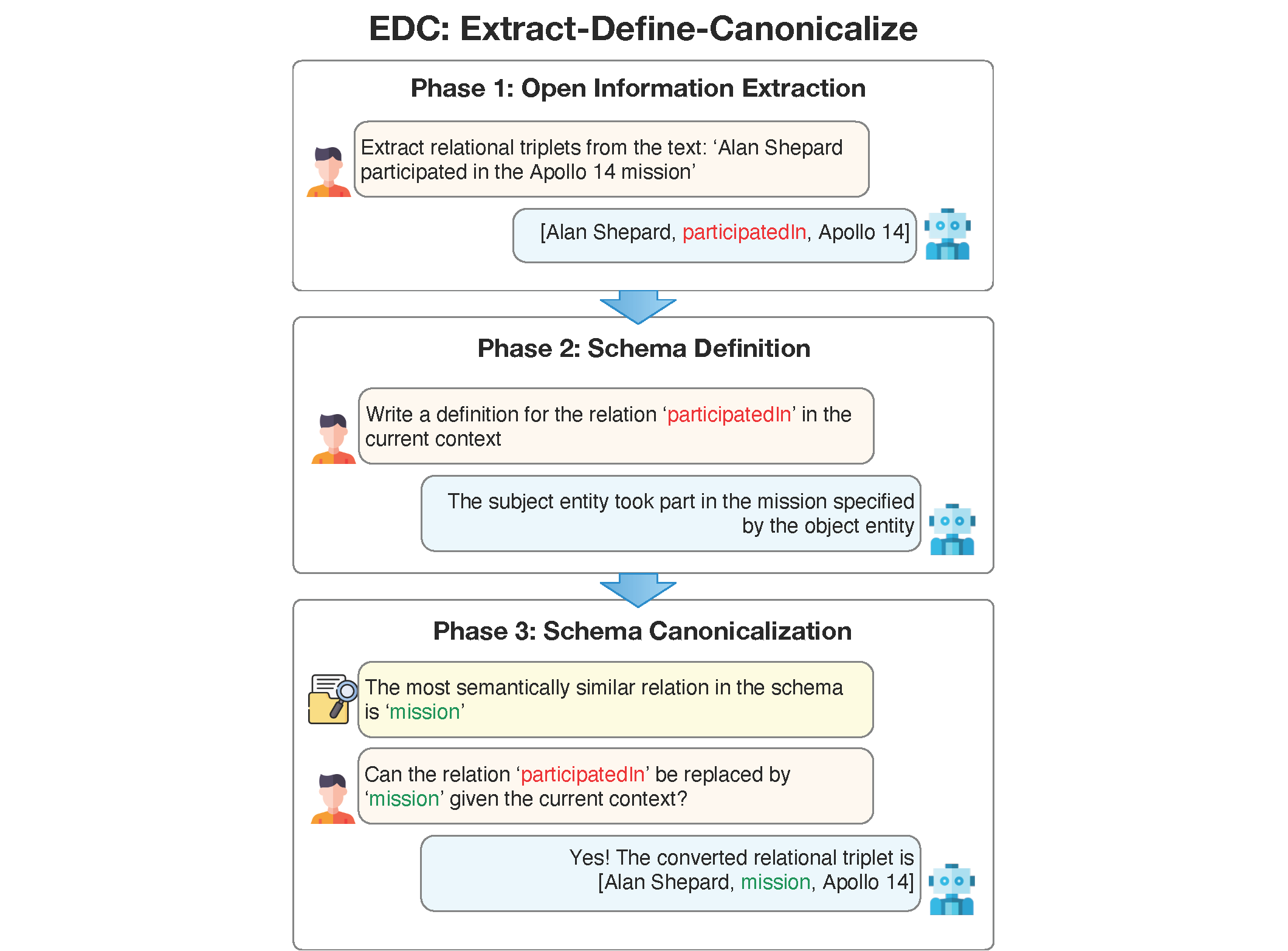
In this section, I will first introduce the EDC framework followed by a description of refinement (EDC+R).
EDC: Extract-Define-Canonicalize
At a high level, EDC decomposes KGC into three connected subtasks.
In the following discussion, a specific input text example will be used for better illustration: “Alan Shepard was born on Nov 18, 1923 and selected by NASA in 1959. He was a member of the Apollo 14 crew.”
Phase 1: Open Information Extraction
Firstly Large Language Models (LLMs) are leveraged for open information extraction. Through few-shot prompting, LLMs identify and extract relational triplets ([Subject, Relation, Object]) from input texts, independent of any specific schema. Using the example above, the prompt is:

The resultant triplets form an open KG, which is forwarded to subsequent phases.
In this case, the resultant triplets are [‘Alan Shepard’, ‘bornOn’, ‘Nov 18, 1923’], [‘Alan Shepard’, ‘participatedIn’, ‘Apollo 14’].
Phase 2: Schema Definition
Next, the LLMs are prompted to provide a natural language definition for each component of the schema induced by the open KG:

The resultant definitions for the schema components are then passed to the next stage as side information used for canonicalization.
This example prompt results in the definitions for (bornOn: The subject entity was born on the date specified by the object entity.) and (participatedIn: The subject entity took part in the event or mission specified by the object entity.).
Phase 3: Schema Canonicalization
The third phase aims to refine the open KG into a canonical form, eliminating redundancies and ambiguities. It starts by vectorizing the definitions of each schema component using a sentence transformer to create embeddings. Canonicalization then proceeds in one of two ways, depending on the availability of a target schema:
- Target Alignment: With an existing target schema, the goal is to identify the most closely related components within the target schema for each element, considering them for canonicalization. To prevent issues of over-generalization, LLMs assess the feasibility of each potential transformation. If a transformation is deemed unreasonable, the component and its related triplets are excluded.
- Self Canonicalization: Absent a target schema, the goal is to consolidate semantically similar schema components, standardizing them to a singular representation to streamline the KG. Starting with an empty canonical schema, it examines the open KG triplets, searching for potential consolidation candidates through vector similarity and LLM verification. Unlike target alignment, components deemed non-transformable are added to the canonical schema, thereby expanding it.
The prompt for the example is:

Note that the choices above are obtained by using vector similarity search. After the LLM makes its choice, the relations are transformed to yield new triplets, which forms the canonicalized KG.
In the example, the new triplets are [‘Alan Shepard’, ‘birthDate’, ‘Nov 18, 1923’], [‘Alan Shepard’, ‘mission’, ‘Apollo 14’].
EDC+R: Iteratively refine EDC with Schema Retriever
The refinement process leverages the data generated by EDC to enhance the quality of the extracted triplets. The authors construct a “hint” for the extraction phase, which comprises two main elements:
- Candidate Entities: The entities extracted by EDC from the previous iteration, and entities extracted from the text using the LLM;

Figure 5: An example of Entity Extraction Prompt. The resultant entities are [‘Alan Shepard’, ‘Nov 18, 1923’, ‘NASA’, ‘1959’, ‘Apollo 14’].
- Candidate Relations: The relations extracted by EDC from the previous cycle and relations retrieved from the pre-defined/canonicalized schema by using a trained Schema Retriever.

By doing so, it can provide a richer pool of candidates for the LLM, which addresses issues where the absence of entities or relations impairs the LLM’s effectiveness; it also serves to aid the OIE by bootstrapping from the previous round.
Schema Retriever: To scale EDC to large schemas, a trained Schema Retriever is employed to help search schemas efficiently. It works in a similar fashion to information retrieval methods based on vector spaces; it projects the schema components and the input text to a vector space such that cosine similarity captures the relevance between the two, i.e., how likely a schema component to be present in the input text.
Back to the example, refinement with the schema retriever adds the following relation to the previous set: [‘Alan Shepard’, ‘selectedByNasa’, ‘1959’]. The relation ‘selectedByNasa’ is rather obscure but was specified in the target schema.
Experiments and Findings
Experimental Setup
- Datasets
This study evaluates EDC using three KGC datasets:
- WebNLG: It contains 1165 pairs of text and triplets. The schema derived from these reference triplets encompasses 159 unique relation types.
- REBEL: The authors select a random sample of 1000 text-triplet pairs from it. This subset induces a schema with 200 distinct relation types.
- Wiki-NRE: The authors sample 1000 text-triplet pairs from it, resulting in a schema with 45 unique relation types.
These datasets were chosen due to their rich variety of relation types. In the experiments, this paper focuses on extracting relations as the only schema component available across all datasets.
- EDC Models
EDC contains multiple modules that are powered by LLMs.
- OIE module: Since it is the key upstream module that determines the semantic content captured in the KG, the authors tested different LLMs of different sizes including GPT-4, GPT-3.5-turbo, and Mistral-7b.
- Framework’s remaining components which required prompting: They used GPT-3.5-turbo.
- Canonicalization phase: The E5-Mistral-7b model was utilized for vector similarity searches without modifications.
- Schema Retriever: It is a fine-tuned variant of the sentence embedding model E5-mistral-7b-instruct.
- Evaluation Criteria and Baselines
- Target Alignment
The authors compare EDC and EDC+R against the specialized trained models for each of the datasets:
- REGEN is the SOTA model for WebNLG.
- GenIE is the state-of-the-art model for REBEL and Wiki-NRE.
This paper uses the WEBNLG evaluation script which computes the Precision, Recall, and F1 scores for the output triplets against the ground truth in a token-based manner. Metrics based on Named Entity Evaluation were used to measure the Precision, Recall, and F1 score in three different ways.
- Exact: Requires a complete match between the candidate and reference triple, disregarding the type (subject, relation, object).
- Partial: Allows for at least a partial match between the candidate and reference triple, disregarding the type.
- Strict: Demands an exact match between the candidate and reference triplet, including the element types.
- Self Canonicalization
For evaluating self-canonicalization performance, comparisons are made with:
- Baseline Open KG, which is the initial open KG output from the OIE phase.
- CESI, recognized as a leading clustering-based approach for open KG canonicalization. By applying CESI to the open KG, the authors aim to contrast its performance against canonicalization by EDC.
The component was evaluated manually, focusing on three key aspects that reflect the intrinsic quality of an extracted KG:
- Precision: The canonicalized triplets remain correct and meaningful with respect to the text compared to the OIE triplets.
- Conciseness: The schema’s brevity is measured by the number of relations types.
- Redundancy: They employ a redundancy score — the average cosine similarity among each canonicalized relation and its nearest counterpart — where low scores indicate that the schema’s relations are semantically distinct.
- Target Alignment
Results

Target Alignment
The bar charts in Figure 7 summarize the Partial F1 scores obtained by EDC and EDC+R on all three datasets with different LLMs for OIE compared against the respective baselines. EDC demonstrates performance that is superior to or on par with the state-of-the-art baselines for all evaluated datasets. Comparing the LLMs, GPT-4 emerges as the top performer, with Mistral-7b and GPT-3.5-turbo exhibiting comparable results.
- Refinement (EDC+R) consistently and significantly enhances performance.
- Post-refinement, the difference in performance between GPT-3.5-turbo and Mistral-7b is larger, suggesting Mistral-7b was not as able to leverage the provided hints. Nevertheless, a single refinement iteration with the hint improved performance for all the tested LLMs.
- From the scores, it appears that EDC performance is significantly better on WebNLG compared to REBEL and Wiki-NRE.
- However, the authors observed that EDC was penalized despite producing valid triplets on the latter datasets, because the reference triplets in these datasets are non-exhaustive. 🎞️
For example, given the text in the REBEL dataset, ‘Romany Love is a 1931 British musical film directed by Fred Paul and starring Esmond Knight, Florence McHugh and Roy Travers.’, EDC extracts: [‘Romany Love’, ‘cast member’, ‘Esmond Knight’], [‘Romany Love’, ‘cast member’, ‘Florence McHugh’], [‘Romany Love’, ‘cast member’, ‘Roy Travers’], which are all semantically correct, but only the first triplet is present in the reference set.
- The datasets also contain reference triplets based on information extraneous to the text.⚽
For example, ‘Daniel is an Ethiopian footballer, who currently plays for Hawassa City S.C.’ has a corresponding reference triplet [‘Hawassa City S.C.’, ‘country’, ‘Ethiopia’].
These issues can be attributed to the distinct methodologies employed in the creation of these datasets.
- However, the authors observed that EDC was penalized despite producing valid triplets on the latter datasets, because the reference triplets in these datasets are non-exhaustive.
- Ablation study on schema retriever.
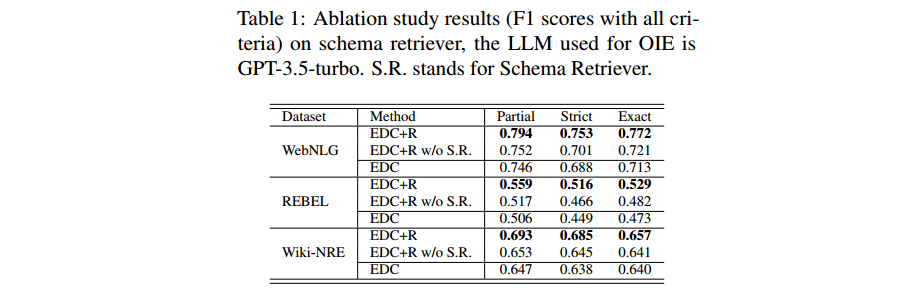
To evaluate the impact of the relations provided by the schema retriever during refinement, the authors conducted an ablation study with GPT-3.5-turbo by removing these relations. The results in Table 1 show that ablating the Schema Retriever leads to a decline in performance. Qualitatively, they find that the schema retriever helps to find relevant relations that are challenging for the LLMs to identify during the OIE stage.
For example, given the text ‘The University of Burgundy in Dijon has 16,800 undergraduate students’, the LLMs extract [‘University of Burgundy’, ‘location’, ‘Dijon’] during OIE. Although semantically correct, this relation overlooks the more specific relation present in the target schema, namely ‘campus’, for denoting university’s location. The schema retriever successfully identifies this finer relation, enabling the LLMs to adjust their extraction to [‘University of Burgundy’, ‘campus’, ‘Dijon’].
Self Canonicalization
The authors evaluate EDC’s self-canonicalization performance utilizing GPT-3.5-turbo for OIE. They omit refinement in Self Canonicalization setting, and in subsequent iterations, the self-constructed canonicalized schema becomes the target schema. They conducted a targeted human evaluation of knowledge graphs. This evaluation involved two independent annotators assessing the reasonableness of triplet extractions from given text without prior knowledge of the system’s details. They observed a high inter-annotator agreement score of 0.94.

The evaluation results and schema metrics are summarized in Table 2.
- While the open KG generated by the OIE stage contains semantically valid triplets, there is a significant degree of redundancy within the resultant schema.
- EDC accurately canonicalizes the open KG and yields a schema that is both more concise and less redundant compared to CESI.
- EDC avoids CESI’s tendency toward over-generalization. ⚰️
For example, the authors observed CESI inappropriately clusters diverse relations such as ‘place of death’, ‘place of birth’, ‘date of death’, ‘date of birth’, and ‘cause of death’ into a single ‘date of death’ category.
Conclusion
In this paper, the authors presented EDC, an LLM-based three-phase framework that addresses the problem of KGC by open information extraction followed by post-hoc canonicalization. Experiments show that EDC and EDC+R are able to extract better KGs than specialized trained models when a target schema is available and dynamically create a schema when none is provided. The scalability and versatility of EDC opens up many opportunities for applications: it allows us to automatically extract high-quality KGs from general text using large schemas like Wikidata and even enrich these schemas with newly discovered relations.
Personal Thoughts
- Overall, this work is interesting, meaningful and solid to me. Additionally, it has a clear structure and enough examples, so that readers can understand it perfectly. Moreover, it’s open source, which helps a lot to reproduce this work.
- However, this work only focuses on relations, so it would be great to extend it to entities and event types.
References
Paper: Zhang, Bowen, and Harold Soh. "Extract, define, canonicalize: An llm-based framework for knowledge graph construction." arXiv preprint arXiv:2404.03868 (2024).
Code: https://github.com/clear-nus/edc